 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Loop in Teleoperation: Episode-Level Data Quality Assessment and Feedback for High-Quality Demonstration Collection
May 25, 2026Industrial automation is at a pivotal moment, as Physical AI is driving a transition from rigid, hand-engineered automation systems toward more flexible and adaptive systems. This shift has created a growing demand for large-scale, real-world robot demonstration data, making teleoperation an increasingly important mechanism for data collection. However, high-quality teleoperated demonstrations remain difficult to obtain in practice, as novice operators often produce episodes that are task-successful but suboptimal for downstream use due to inefficient motion, repeated corrections, or operation near robot joint limits. We present a Data Quality Assessment and Feedback (DQAF) framework that closes the loop in teleoperation by providing immediate post-episode feedback grounded in semantic task progress and robot telemetry. The framework extracts quality relevant signals such as sub-task progress, motion smoothness, stalls, kinematic limits and converts them into structured quality assessments and actionable natural-language feedback. Unlike binary success or failure feedback, the proposed system explains why an episode is suboptimal and highlights specific behaviors to correct in the next trial. We evaluate the framework through a diagnostic validation study and a pilot user study. In the validation study, the system is compared with a human reviewer during dataset curation, producing rejection reasons and actionable feedback for improvement. In the pilot study with three novice operators across two manipulation tasks, the operator who received the systems immediate, automated post-episode feedback improved faster than those who did not, producing higher-quality demonstrations sooner.
A Factory-Floor Deployment Case Study of VLA Pipelines for Industrial Packaging Task: Workflow, Failures, and Lessons
May 25, 2026Vision-Language-Action (VLA) policies have shown promising manipulation capabilities, yet their practical impact is often limited by the reliability demands of real-world deployment. We present a deployment study of an industrial packaging task at Siemens Factory (GWE, Erlangen, Germany), where a robot must pick a transparent accessory bag from a cluttered pile, insert it into the remaining cavity of a cardboard package, and ensure that the bag and its contents remain below the closing plane. Our goal is to understand the practical effort required to adapt a pretrained Pi0.5 policy to a single factory-floor task through iterative fine-tuning and deployment-driven refinement. The pipeline consists of repeated loops of data collection, curation, fine-tuning, evaluation, and targeted recovery data collection. We have accumulated 2535 episodes (10 hours) from the on-site factory settings. In this paper, we contribute an empirical account of a factory-floor VLA deployment, highlighting recurring failure modes and lessons that inform how to improve the deployment workflow.
SheetMind: An End-to-End LLM-Powered Multi-Agent Framework for Spreadsheet Automation
Jun 14, 2025


We present SheetMind, a modular multi-agent framework powered by large language models (LLMs) for spreadsheet automation via natural language instructions. The system comprises three specialized agents: a Manager Agent that decomposes complex user instructions into subtasks; an Action Agent that translates these into structured commands using a Backus Naur Form (BNF) grammar; and a Reflection Agent that validates alignment between generated actions and the user's original intent. Integrated into Google Sheets via a Workspace extension, SheetMind supports real-time interaction without requiring scripting or formula knowledge. Experiments on benchmark datasets demonstrate an 80 percent success rate on single step tasks and approximately 70 percent on multi step instructions, outperforming ablated and baseline variants. Our results highlight the effectiveness of multi agent decomposition and grammar based execution for bridging natural language and spreadsheet functionalities.
Learning on the Job: Self-Rewarding Offline-to-Online Finetuning for Industrial Insertion of Novel Connectors from Vision
Oct 27, 2022Learning-based methods in robotics hold the promise of generalization, but what can be done if a learned policy does not generalize to a new situation? In principle, if an agent can at least evaluate its own success (i.e., with a reward classifier that generalizes well even when the policy does not), it could actively practice the task and finetune the policy in this situation. We study this problem in the setting of industrial insertion tasks, such as inserting connectors in sockets and setting screws. Existing algorithms rely on precise localization of the connector or socket and carefully managed physical setups, such as assembly lines, to succeed at the task. But in unstructured environments such as homes or even some industrial settings, robots cannot rely on precise localization and may be tasked with previously unseen connectors. Offline reinforcement learning on a variety of connector insertion tasks is a potential solution, but what if the robot is tasked with inserting previously unseen connector? In such a scenario, we will still need methods that can robustly solve such tasks with online practice. One of the main observations we make in this work is that, with a suitable representation learning and domain generalization approach, it can be significantly easier for the reward function to generalize to a new but structurally similar task (e.g., inserting a new type of connector) than for the policy. This means that a learned reward function can be used to facilitate the finetuning of the robot's policy in situations where the policy fails to generalize in zero shot, but the reward function generalizes successfully. We show that such an approach can be instantiated in the real world, pretrained on 50 different connectors, and successfully finetuned to new connectors via the learned reward function. Videos can be viewed at https://sites.google.com/view/learningonthejob
PogoDrone: Design, Model, and Control of a Jumping Quadrotor
Apr 01, 2022
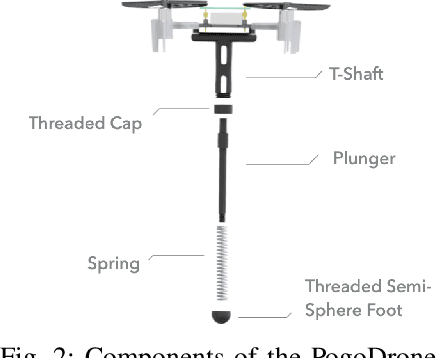
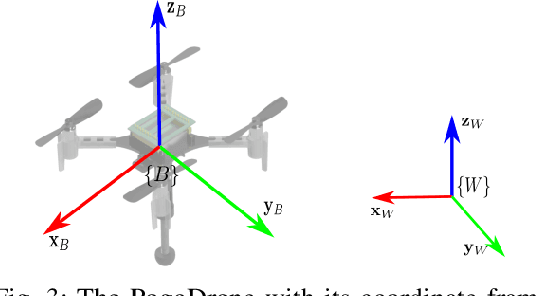
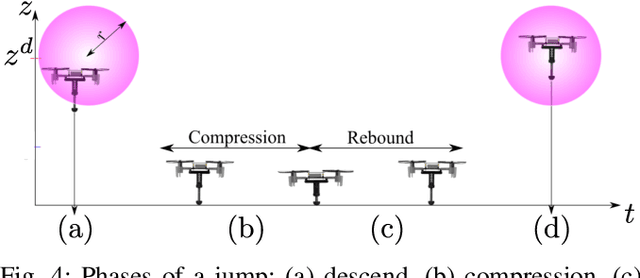
We present a design, model, and control for a novel jumping-flying robot that is called PogoDrone. The robot is composed of a quadrotor with a passive mechanism for jumping. The robot can continuously jump in place or fly like a normal quadrotor. Jumping in place allows the robot to quickly move and operate very close to the ground. For instance, in agricultural applications, the jumping mechanism allows the robot to take samples of soil. We propose a hybrid controller that switches from attitude to position control to allow the robot to fall horizontally and recover to the original position. We compare the jumping mode with the hovering mode to analyze the energy consumption. In simulations, we evaluate the effect of different factors on energy consumption. In real experiments, we show that our robot can repeatedly impact the ground, jump, and fly in a physical environment.